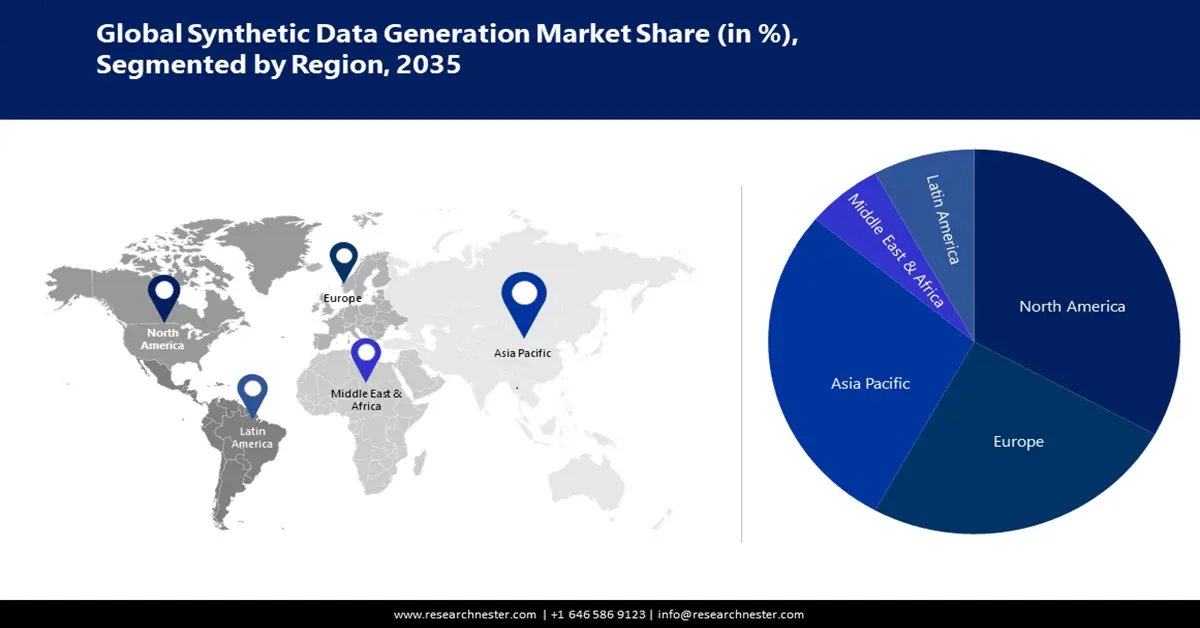
Synthetic Data Generation Market Regional Analysis:
North American Market Insights
The synthetic data generation market in North America is attributed to hold the largest revenue share of about 33% as it is a center for technical development, with a particular emphasis on data-driven breakthroughs, AI, and machine learning. Due to rising establishment of start-ups, tech firms, and research institutions in this region, there is a surge in high-quality synthetic data for performing experiments and training AI models. The presence of major market players further propels the market expansion in the region. Organizations in the U.S. seek robust solutions to protect sensitive information and curb data breach cases. It has been estimated that the average cost of a data breach in the country is USD 9.32 million in 2024. Additionally, synthetic data is utilized by researchers for drug trials without exposing sensitive patient information.
Asia Pacific Market Insights
The synthetic data generation market in the Asia Pacific is projected to hold the second-largest revenue share of about 38%. The countries such as China and Japan are home to remarkable technology-oriented companies that give importance to research and development. The governments are prioritizing investment in big data, AI, and machine learning strategies. Synthetic data is being leveraged in numerous ways to enhance road safety. For instance, according to the International Trade Administration in September 2024, Japan’s Ministry of Internal Affairs and Communication predicts that Japan’s AI systems market will flourish to almost USD 7.3 billion. Osaka University researchers have fabricated an ultra-modern framework that can automatically produce synthetic datasets from a city digital twin.