Synthetic Data Generation Market Outlook:
Synthetic Data Generation Market size was over USD 447.16 million in 2025 and is projected to reach USD 8.79 billion by 2035, witnessing around 34.7% CAGR during the forecast period i.e., between 2026-2035. In the year 2026, the industry size of synthetic data generation is evaluated at USD 586.81 million.
The market growth can be primarily attributed to the rising utilization of synthetic data in calibrating and developing sensors used in autonomous vehicles. Additionally, automotive engineers utilize synthetic data to fabricate virtual environments that stimulate real-world driving conditions. It has been estimated that by 2035, autonomous driving could create USD 300 billion to USD 430 billion in revenue. The data published by the National Association of Insurance Commissioners; expects there to will be 4.5 million self-driving vehicles on the roads in U.S. roads by 2030. These factors are projected to fuel the synthetic data generation market during the forecast period.
Synthetic data is used to train AI models in various fields to enhance the model performance by eliminating bias and adding fresh domain knowledge. Other growing uses of generated data include training models in the absence of real data. Research Nester suggests that currently 34% of the companies currently using Artificial Intelligence and an additional 42% are exploring the field. In the rapidly evolving domain of artificial intelligence, the utilization and creation of synthetic data sets have become increasingly significant.
Key Synthetic Data Generation Market Insights Summary:
Regional Highlights:
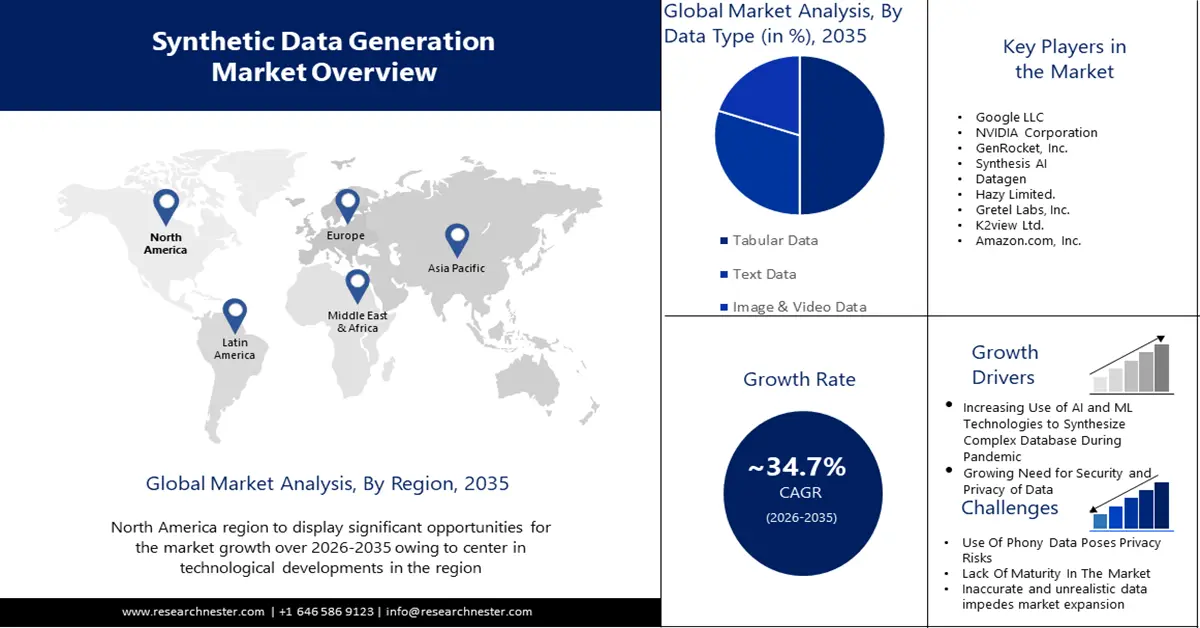
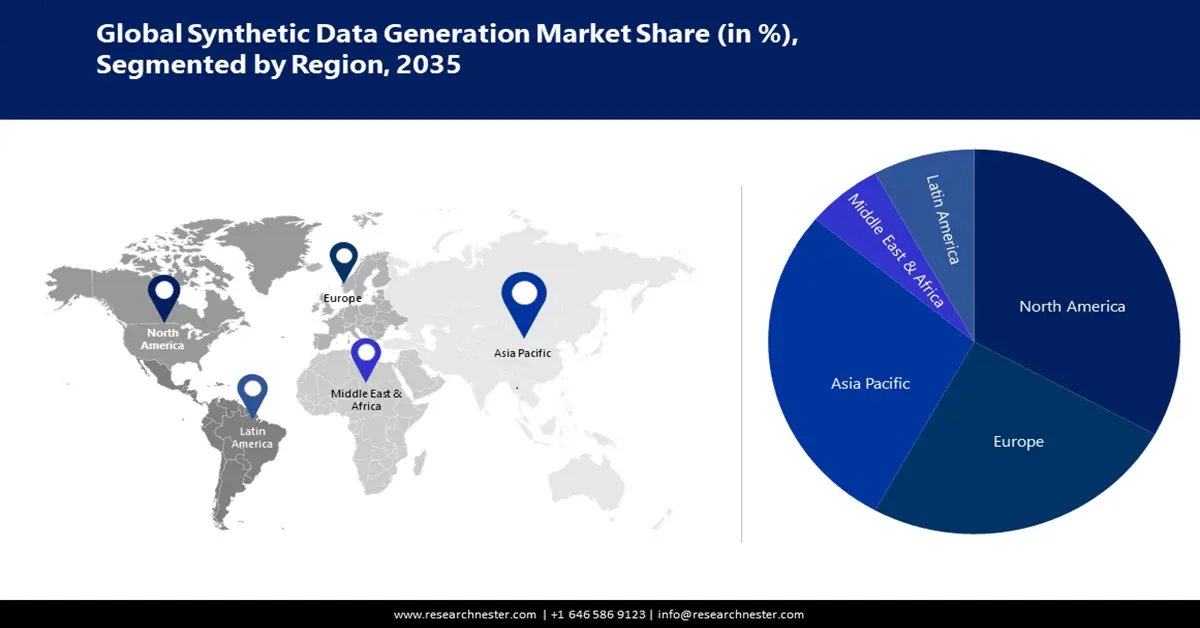
- Asia Pacific synthetic data generation market will dominate more than 38% share, propelled by rising R&D investments, AI strategies, and smart synthetic data applications, forecast period 2026–2035.
- North America market will capture a 33% share, driven by the concentration of AI/ML innovation, and demand for secure synthetic data, forecast period 2026–2035.
Segment Insights:
- The tabular data segment in the synthetic data generation market is expected to achieve a 50% share by 2035, driven by increased need for synthetic tabular data due to privacy concerns and data security.
- The test data management segment in the synthetic data generation market is projected to capture a 35% share by 2035, driven by the rising requirement for high-quality data for testing and validation.
Key Growth Trends:
- Growing need for data security
- Increased use of Large Language Models (LLM)
Major Challenges:
- Occurrence of inaccurate and unrealistic data impedes market expansion
- Associated ethical considerations
Key Players: Google LLC, NVIDIA Corporation, GenRocket, Inc., Synthesis AI, Datagen, Hazy Limited., Gretel Labs, Inc., K2view Ltd., Amazon.com, Inc..
Global Synthetic Data Generation Market Forecast and Regional Outlook:
Market Size & Growth Projections:
- 2025 Market Size: USD 447.16 million
- 2026 Market Size: USD 586.81 million
- Projected Market Size: USD 8.79 billion by 2035
- Growth Forecasts: 34.7% CAGR (2026-2035)
Key Regional Dynamics:
- Largest Region: Asia Pacific (38% Share by 2035)
- Fastest Growing Region: Asia Pacific
- Dominating Countries: United States, China, Germany, United Kingdom, Japan
- Emerging Countries: China, India, Brazil, Mexico, Singapore
Last updated on : 16 September, 2025
Synthetic Data Generation Market Growth Drivers and Challenges:
Growth Drivers
-
Growing need for data security: Synthetic data has proven to be an efficacious tool in unleashing the possibilities of data without compromising privacy. Market players in various sectors such as health, finance, insurance, etc. are opting for synthetic data to maximize the utility of data while also shielding consumer privacy. Additionally, synthetic data plays a prominent role in addressing crucial issues such as fraud detection, risk modeling, etc. The alarming rate of cases of data breaches is compelling market players to adopt mitigation methods. According to a report published by Harvard Business Review in February 2024, there was a 20% surge in data breach cases from 2022 to 2023 globally. The rising need for security and privacy of data, the market is projected to witness significant growth.
-
Increased use of Large Language Models (LLM): Use cases of large language models are in content generation, translation and localization, chatbots, personal assistance, etc. According to data published by the World Economic Forum in October 2023, social networking sites such as WhatsApp, Instagram, and Facebook will interact with almost 30 AI chatbots by parent company Meta to revolutionize their social media users' experience. Various end users use these language models for code generation, fraud detection, image annotation, text production, and conversational AI. Synthetic data makes these chatbots accurate and useful for the consumer.
- Use of AI and ML technologies to synthesize complex databases during the pandemic: The advent of the COVID-19 pandemic reflects the characteristics of the patients on a wide scale and recreates the impact of the pandemic over time and across densely tested geographic areas. There is a surge in the number of epidemiologists all across the world. For instance, a report published by the U.S. Bureau of Labor Statistics in May 2023 stated that the number of epidemiologists employed is 10,230. They use synthetic data on a large scale to deduce the repercussions of the pandemic.
Challenges
-
Occurrence of inaccurate and unrealistic data impedes market expansion: Users can test and share virtual replicas of datasets created using synthetic data production. Furthermore, it is challenging for this method to capture the fine details of specialist models and real-world photographs. Maintaining the synthetic dataset over time is difficult since it relies on real-world data and varies as a result of inventions and advancements. Organizations should therefore routinely verify the accuracy and dependability of the synthetic data. This aspect substantially impedes the growth of the synthetic data generation market by degrading the quality and realism of the synthetic data.
-
Associated ethical considerations: The utilization of synthetic data increases the ethical considerations associated with data privacy and assent in the generated data. Various frameworks for governing data usage and protection may put limitations on the usage of synthetic data and hinder scalability and adoption. The potential for bias and privacy concerns are projected to hinder the market growth.
Synthetic Data Generation Market Size and Forecast:
| Report Attribute | Details |
|---|---|
|
Base Year |
2025 |
|
Forecast Period |
2026-2035 |
|
CAGR |
34.7% |
|
Base Year Market Size (2025) |
USD 447.16 million |
|
Forecast Year Market Size (2035) |
USD 8.79 billion |
|
Regional Scope |
|
Synthetic Data Generation Market Segmentation:
Data Type Segment Analysis
Based on data type, tabular data in the synthetic data generation market is anticipated to hold the largest revenue share of about 50% during the forecast period. Recently, privacy concerns have made it difficult for businesses to get real-life data. Due to these difficulties, synthetic data that resembles real data is produced and can be kept in an organized tabular manner. This increases the need for tabular data, which is anticipated to grow at a notable CAGR throughout the projected period. Businesses can improve operational data security and privacy by utilizing Generative Adversarial Networks (GANs) to create synthetic tabular data.
Application Segment Analysis
Based on application, the test data management segment in the synthetic data generation market is expected to hold the largest share, about 35%, during the forecast period. The rising requirement for high-quality data for testing and validation will drive the market. Test data management allows the developers to test applications with the use of real-world data, without putting data at risk. For instance, the Infosys test data management suite provides web-based tools for centralized test data management. This suite renders an easy and single-use interface for data and testing provisioning teams. The tool kit comes with test data generation, masking, and extraction capabilities along with data request-based workflow.
Our in-depth analysis of the global synthetic data generation market includes the following segments:
|
Component |
|
|
Deployment Mode |
|
|
Modelling Type |
|
|
Offering |
|
|
Data Type |
|
|
Vertical |
|

Vishnu Nair
Head - Global Business DevelopmentCustomize this report to your requirements — connect with our consultant for personalized insights and options.
Synthetic Data Generation Market Regional Analysis:
North American Market Insights
The synthetic data generation market in North America is attributed to hold the largest revenue share of about 33% as it is a center for technical development, with a particular emphasis on data-driven breakthroughs, AI, and machine learning. Due to rising establishment of start-ups, tech firms, and research institutions in this region, there is a surge in high-quality synthetic data for performing experiments and training AI models. The presence of major market players further propels the market expansion in the region. Organizations in the U.S. seek robust solutions to protect sensitive information and curb data breach cases. It has been estimated that the average cost of a data breach in the country is USD 9.32 million in 2024. Additionally, synthetic data is utilized by researchers for drug trials without exposing sensitive patient information.
Asia Pacific Market Insights
The synthetic data generation market in the Asia Pacific is projected to hold the second-largest revenue share of about 38%. The countries such as China and Japan are home to remarkable technology-oriented companies that give importance to research and development. The governments are prioritizing investment in big data, AI, and machine learning strategies. Synthetic data is being leveraged in numerous ways to enhance road safety. For instance, according to the International Trade Administration in September 2024, Japan’s Ministry of Internal Affairs and Communication predicts that Japan’s AI systems market will flourish to almost USD 7.3 billion. Osaka University researchers have fabricated an ultra-modern framework that can automatically produce synthetic datasets from a city digital twin.
Synthetic Data Generation Market Players:
- Microsoft Corporation
- Company Overview
- Business Strategy
- Key Product Offerings
- Financial Performance
- Key Performance Indicators
- Risk Analysis
- Recent Development
- Regional Presence
- SWOT Analysis
- Google LLC
- NVIDIA Corporation
- GenRocket, Inc.
- Synthesis AI
- Datagen
- Hazy Limited.
- Gretel Labs, Inc.
- K2view Ltd.
- Amazon.com, Inc.
Recent Developments
- In March 2024, Hazy and Unbanx announced their collaboration Open Banking data ownership platform. This is a collective effort by both companies to deploy ethical synthetic data cooperatives for financial transaction data catering to hedge funds, analysts, and other financial institutions.
- In June 2024, NVIDIA Nemotron-4 340B, optimized for NVIDIA TensorRT-LLM and NVIDIA NeMo for healthcare, manufacturing, retail, and finance, among several others to develop commercial applications.
- In September 2024, Amazon launched Amazon Bedrock which is useful in generating Python code for synthetic data creation. The Amazon Bedrock tool helps customers in building and scaling generative AI applications. It is a fully managed service for building generative AI applications.
- In October 2024, Gretel and Google Cloud joined hands to simplify synthetic data generation for data analysts within BigQuery. The integration allows users to make privacy-preserving synthetic versions of their BigQuery data sets. The partnership empowers the customers to protect data privacy, enhance accessibility, and accelerate testing and development.
- In October 2024, Teledyne FLIR brought Prism AIMMGen to the market, which is an ITAR-free AI model synthetic data generation service for system integrators to create AI/ML products for first response, commercial, and defense applications.
- In October 2024, Betterdata, MOSTLY AI, DataCebo, and Rockfish Data received contractual awards from the Department of Homeland Security (DHS) Science and Technology Directorate (S&T) to develop synthetic data capabilities that can generate real data patterns while mitigating security threats. The privacy-preserving generative data platforms are set to accelerate AI capabilities in enterprise-grade applications.
- Report ID: 5711
- Published Date: Sep 16, 2025
- Report Format: PDF, PPT
- Explore a preview of key market trends and insights
- Review sample data tables and segment breakdowns
- Experience the quality of our visual data representations
- Evaluate our report structure and research methodology
- Get a glimpse of competitive landscape analysis
- Understand how regional forecasts are presented
- Assess the depth of company profiling and benchmarking
- Preview how actionable insights can support your strategy
Explore real data and analysis
Frequently Asked Questions (FAQ)
Synthetic Data Generation Market Report Scope
Free Sample includes current and historical market size, growth trends, regional charts & tables, company profiles, segment-wise forecasts, and more.
Connect with our Expert




Copyright @ 2026 Research Nester. All Rights Reserved.
