Perspectives du marché de la génération de données synthétiques :
Le marché de la génération de données synthétiques représentait plus de 447,16 millions de dollars US en 2025 et devrait atteindre 8,79 milliards de dollars US d'ici 2035, avec un TCAC d'environ 34,7 % sur la période 2026-2035. En 2026, la taille du secteur de la génération de données synthétiques est estimée à 586,81 millions de dollars US.
La croissance du marché est principalement due à l'utilisation croissante de données synthétiques pour l'étalonnage et le développement des capteurs des véhicules autonomes. De plus, les ingénieurs automobiles utilisent ces données pour créer des environnements virtuels simulant des conditions de conduite réelles. On estime que d'ici 2035, la conduite autonome pourrait générer entre 300 et 430 milliards de dollars de revenus. Selon les données publiées par la National Association of Insurance Commissioners, 4,5 millions de véhicules autonomes devraient circuler sur les routes américaines d'ici 2030. Ces facteurs devraient stimuler le marché de la génération de données synthétiques au cours de la période de prévision.
Les données synthétiques sont utilisées pour entraîner des modèles d'IA dans divers domaines afin d'améliorer leurs performances en éliminant les biais et en enrichissant les connaissances du domaine. Parmi les autres utilisations croissantes des données générées figure l'entraînement de modèles en l'absence de données réelles. Research Nester indique qu'actuellement, 34 % des entreprises utilisent l'intelligence artificielle et que 42 % explorent ce domaine. Dans le domaine en rapide évolution de l'intelligence artificielle, l'utilisation et la création d'ensembles de données synthétiques prennent une importance croissante.
Clé Génération de données synthétiques Résumé des informations sur le marché:
Points forts régionaux :
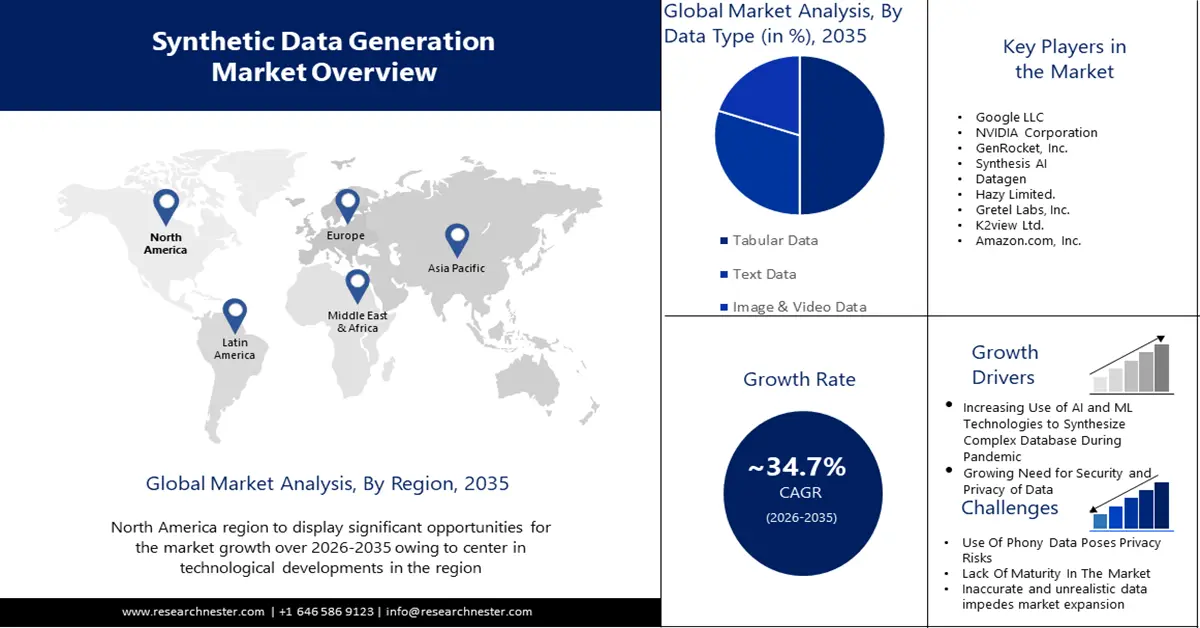
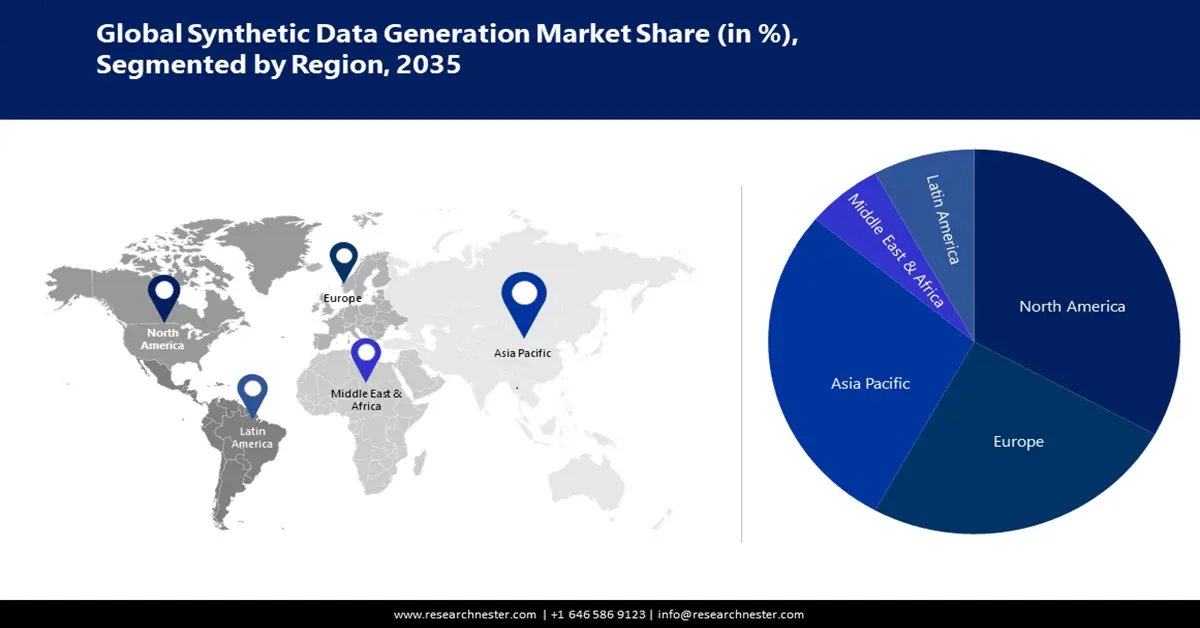
- Le marché de la génération de données synthétiques en Asie-Pacifique dominera le marché avec plus de 38 % de parts de marché, grâce à la hausse des investissements en R&D, aux stratégies d'IA et aux applications de données synthétiques intelligentes, sur la période de prévision 2026-2035.
- Le marché nord-américain s'accaparera une part de marché de 33 %, porté par la concentration des innovations en IA/ML et la demande de données synthétiques sécurisées, sur la période de prévision 2026-2035.
Analyses sectorielles :
- Le segment des données tabulaires sur le marché de la génération de données synthétiques devrait atteindre 50 % de part de marché d’ici 2035, en raison du besoin croissant de données tabulaires synthétiques lié aux préoccupations en matière de confidentialité et de sécurité des données.
- Le segment de la gestion des données de test sur le marché de la génération de données synthétiques devrait atteindre 35 % de part de marché d’ici 2035, en raison du besoin croissant de données de haute qualité pour les tests et la validation.
Principales tendances de croissance :
- Besoin croissant de sécurité des données
- Utilisation croissante des modèles de langage étendus (LLM)
Défis majeurs :
- La présence de données inexactes et irréalistes freine l'expansion du marché
- Considérations éthiques associées
Acteurs clés :Google LLC, NVIDIA Corporation, GenRocket, Inc., Synthesis AI, Datagen, Hazy Limited., Gretel Labs, Inc., K2view Ltd., Amazon.com, Inc.
Mondial Génération de données synthétiques Marché Prévisions et perspectives régionales:
Taille du marché et projections de croissance :
- Taille du marché 2025 : 447,16 millions USD
- Taille du marché 2026 : 586,81 millions USD
- Taille du marché projetée : 8,79 milliards USD d'ici 2035
- Prévisions de croissance : TCAC de 34,7 % (2026-2035)
Dynamiques régionales clés :
- Plus grande région : Asie-Pacifique (part de 38 % d’ici 2035)
- Région à la croissance la plus rapide : Asie-Pacifique
- Pays dominants : États-Unis, Chine, Allemagne, Royaume-Uni, Japon
- Pays émergents : Chine, Inde, Brésil, Mexique, Singapour
Last updated on : 16 September, 2025
Moteurs de croissance et défis du marché de la génération de données synthétiques :
Moteurs de croissance
Besoin croissant de sécurité des données : Les données synthétiques se sont avérées efficaces pour exploiter pleinement le potentiel des données sans compromettre la confidentialité. Les acteurs de divers secteurs, tels que la santé, la finance et les assurances, optent pour les données synthétiques afin d'optimiser leur utilité tout en protégeant la confidentialité des consommateurs. De plus, les données synthétiques jouent un rôle essentiel pour répondre à des enjeux cruciaux tels que la détection des fraudes et la modélisation des risques. Le taux alarmant de violations de données incite les acteurs du marché à adopter des mesures d'atténuation. Selon un rapport publié par la Harvard Business Review en février 2024, les violations de données ont augmenté de 20 % entre 2022 et 2023 à l'échelle mondiale. Face à ce besoin croissant de sécurité et de confidentialité des données, le marché devrait connaître une croissance significative.
Utilisation croissante des modèles linguistiques étendus (MLE) : Les modèles linguistiques étendus sont notamment utilisés dans la génération de contenu, la traduction et la localisation, les chatbots, l'assistance personnelle, etc. Selon les données publiées par le Forum économique mondial en octobre 2023, les réseaux sociaux tels que WhatsApp, Instagram et Facebook interagiront avec près de 30 chatbots IA développés par la société mère Meta afin de révolutionner l'expérience utilisateur. Ces modèles linguistiques sont utilisés par divers utilisateurs pour la génération de code, la détection de fraude, l'annotation d'images, la production de texte et l'IA conversationnelle. Les données synthétiques rendent ces chatbots précis et utiles pour le consommateur.
- Utilisation des technologies d'IA et d'apprentissage automatique pour synthétiser des bases de données complexes pendant la pandémie : L'apparition de la pandémie de COVID-19 reflète les caractéristiques des patients à grande échelle et reproduit l'impact de la pandémie au fil du temps et dans des zones géographiques fortement testées. On observe une forte augmentation du nombre d'épidémiologistes dans le monde entier. Par exemple, un rapport publié par le Bureau of Labor Statistics des États-Unis en mai 2023 indiquait que le nombre d'épidémiologistes employés s'élevait à 10 230. Ce bureau utilise des données synthétiques à grande échelle pour déduire les répercussions de la pandémie.
Défis
La présence de données inexactes et irréalistes freine l'expansion du marché : les utilisateurs peuvent tester et partager des répliques virtuelles d'ensembles de données créés grâce à la production de données synthétiques. De plus, cette méthode complique la capture des détails précis des modèles spécialisés et des photographies réelles. La maintenance des données synthétiques au fil du temps est complexe, car elles reposent sur des données réelles et varient en fonction des inventions et des avancées. Les organisations doivent donc vérifier régulièrement l'exactitude et la fiabilité des données synthétiques. Cet aspect freine considérablement la croissance du marché de la production de données synthétiques en dégradant leur qualité et leur réalisme.
Considérations éthiques associées : L'utilisation de données synthétiques accroît les considérations éthiques liées à la confidentialité des données et au consentement des utilisateurs. Différents cadres régissant l'utilisation et la protection des données peuvent limiter l'utilisation des données synthétiques et freiner leur évolutivité et leur adoption. Le risque de biais et les préoccupations en matière de confidentialité devraient freiner la croissance du marché.
Taille et prévisions du marché de la génération de données synthétiques :
| Attribut du rapport | Détails |
|---|---|
|
Année de base |
2025 |
|
Période de prévision |
2026-2035 |
|
TCAC |
34,7% |
|
Taille du marché de l'année de référence (2025) |
447,16 millions USD |
|
Taille du marché prévue pour l'année (2035) |
8,79 milliards de dollars |
|
Portée régionale |
|
Segmentation du marché de la génération de données synthétiques :
Analyse des segments de types de données
Selon le type de données, les données tabulaires devraient représenter la part de marché la plus importante du marché de la génération de données synthétiques, soit environ 50 % au cours de la période de prévision. Récemment, les préoccupations en matière de confidentialité ont rendu difficile l'accès des entreprises à des données réelles. De ce fait, des données synthétiques similaires aux données réelles sont produites et peuvent être conservées sous forme de tableaux organisés. Cela accroît le besoin de données tabulaires, dont le taux de croissance annuel composé (TCAC) devrait augmenter considérablement tout au long de la période de prévision. Les entreprises peuvent améliorer la sécurité et la confidentialité de leurs données opérationnelles en utilisant des réseaux antagonistes génératifs (GAN) pour créer des données tabulaires synthétiques.
Analyse des segments d'application
En fonction des applications, le segment de la gestion des données de test sur le marché de la génération de données synthétiques devrait détenir la part la plus importante, environ 35 %, au cours de la période de prévision. La demande croissante de données de haute qualité pour les tests et la validation stimulera le marché. La gestion des données de test permet aux développeurs de tester des applications à partir de données réelles, sans compromettre les données. Par exemple, la suite de gestion des données de test Infosys propose des outils web pour une gestion centralisée des données de test. Cette suite offre une interface simple et unique pour les équipes de provisionnement des données et des tests. Cette boîte à outils comprend des fonctionnalités de génération, de masquage et d'extraction de données de test, ainsi qu'un workflow basé sur les requêtes de données.
Notre analyse approfondie du marché mondial de la génération de données synthétiques comprend les segments suivants :
Composant |
|
Mode de déploiement |
|
Type de modélisation |
|
Offre |
|
Type de données |
|
Verticale |
|

Vishnu Nair
Responsable du développement commercial mondialPersonnalisez ce rapport selon vos besoins — contactez notre consultant pour des informations et des options personnalisées.
Analyse régionale du marché de la génération de données synthétiques :
Aperçu du marché nord-américain
Le marché de la génération de données synthétiques en Amérique du Nord est considéré comme détenant la plus grande part de chiffre d'affaires, soit environ 33 %, car il s'agit d'un pôle de développement technique, avec un accent particulier sur les avancées technologiques basées sur les données, l'IA et l'apprentissage automatique. L'implantation croissante de start-ups, d'entreprises technologiques et d'instituts de recherche dans cette région entraîne une forte augmentation des données synthétiques de haute qualité pour la réalisation d'expériences et l'entraînement de modèles d'IA. La présence d'acteurs majeurs sur le marché stimule également l'expansion du marché dans la région. Les organisations américaines recherchent des solutions robustes pour protéger les informations sensibles et limiter les violations de données. Le coût moyen d'une violation de données dans le pays a été estimé à 9,32 millions de dollars en 2024. De plus, les données synthétiques sont utilisées par les chercheurs pour les essais cliniques sans exposer les informations sensibles des patients.
Aperçu du marché de l'Asie-Pacifique
Le marché de la génération de données synthétiques en Asie-Pacifique devrait représenter la deuxième part de marché, soit environ 38 %. Des pays comme la Chine et le Japon abritent des entreprises technologiques remarquables qui accordent une grande importance à la recherche et au développement. Les gouvernements accordent la priorité aux investissements dans le big data, l'IA et les stratégies d'apprentissage automatique. Les données synthétiques sont exploitées de multiples façons pour améliorer la sécurité routière. Par exemple, selon l'Administration du commerce international (ITA) en septembre 2024, le ministère japonais de l'Intérieur et des Communications prévoyait que le marché japonais des systèmes d'IA atteindrait près de 7,3 milliards de dollars. Des chercheurs de l'Université d'Osaka ont mis au point un cadre ultramoderne capable de produire automatiquement des ensembles de données synthétiques à partir d'un jumeau numérique urbain.
Acteurs du marché de la génération de données synthétiques :
- Microsoft Corporation
- Présentation de l'entreprise
- Stratégie d'entreprise
- Offres de produits clés
- Performance financière
- Indicateurs clés de performance
- Analyse des risques
- Développement récent
- Présence régionale
- Analyse SWOT
- Google LLC
- NVIDIA Corporation
- GenRocket, Inc.
- IA de synthèse
- Datagen
- Hazy Limitée.
- Gretel Labs, Inc.
- K2view Ltée.
- Amazon.com, Inc.
Développements récents
- En mars 2024, Hazy et Unbanx ont annoncé leur collaboration autour d'une plateforme de propriété de données Open Banking. Il s'agit d'un effort collectif des deux entreprises visant à déployer des coopératives de données synthétiques éthiques pour les données de transactions financières destinées aux fonds spéculatifs, aux analystes et autres institutions financières.
- En juin 2024, NVIDIA Nemotron-4 340B, optimisé pour NVIDIA TensorRT-LLM et NVIDIA NeMo pour les soins de santé, la fabrication, la vente au détail et la finance, entre autres, pour développer des applications commerciales.
- En septembre 2024, Amazon a lancé Amazon Bedrock, un outil de génération de code Python pour la création de données synthétiques. Cet outil aide les clients à créer et à faire évoluer leurs applications d'IA générative. Il s'agit d'un service entièrement géré pour la création d'applications d'IA générative.
- En octobre 2024, Gretel et Google Cloud se sont associés pour simplifier la génération de données synthétiques pour les analystes de données au sein de BigQuery. Cette intégration permet aux utilisateurs de créer des versions synthétiques de leurs jeux de données BigQuery tout en préservant la confidentialité. Ce partenariat permet aux clients de protéger la confidentialité des données, d'améliorer l'accessibilité et d'accélérer les tests et le développement.
- En octobre 2024, Teledyne FLIR a lancé sur le marché Prism AIMMGen, un service de génération de données synthétiques de modèles d'IA sans ITAR permettant aux intégrateurs de systèmes de créer des produits d'IA/ML pour les applications de première intervention, commerciales et de défense.
- En octobre 2024, Betterdata, MOSTLY AI, DataCebo et Rockfish Data ont reçu des contrats de la Direction des sciences et technologies (S&T) du Département de la Sécurité intérieure (DHS) pour développer des capacités de données synthétiques capables de générer des modèles de données réels tout en atténuant les menaces de sécurité. Ces plateformes de données génératives, respectueuses de la confidentialité, devraient accélérer le développement des capacités d'IA dans les applications d'entreprise.
- Report ID: 5711
- Published Date: Sep 16, 2025
- Report Format: PDF, PPT
- Découvrez un aperçu des principales tendances du marché et des insights
- Passez en revue des tableaux de données d’échantillon et des analyses par segment
- Découvrez la qualité de nos représentations visuelles de données
- Évaluez la structure de notre rapport et notre méthodologie de recherche
- Jetez un coup d’œil à l’analyse du paysage concurrentiel
- Comprenez comment les prévisions régionales sont présentées
- Évaluez la profondeur des profils d’entreprise et du benchmarking
- Visualisez comment des insights exploitables peuvent soutenir votre stratégie
Explorez des données et des analyses réelles
Questions fréquemment posées (FAQ)
À propos de ce rapport
Contactez notre expert

Rapport, 2026-2035



Droits d’auteur © 2026 Research Nester. Tous droits réservés.
