Marktausblick für die Generierung synthetischer Daten:
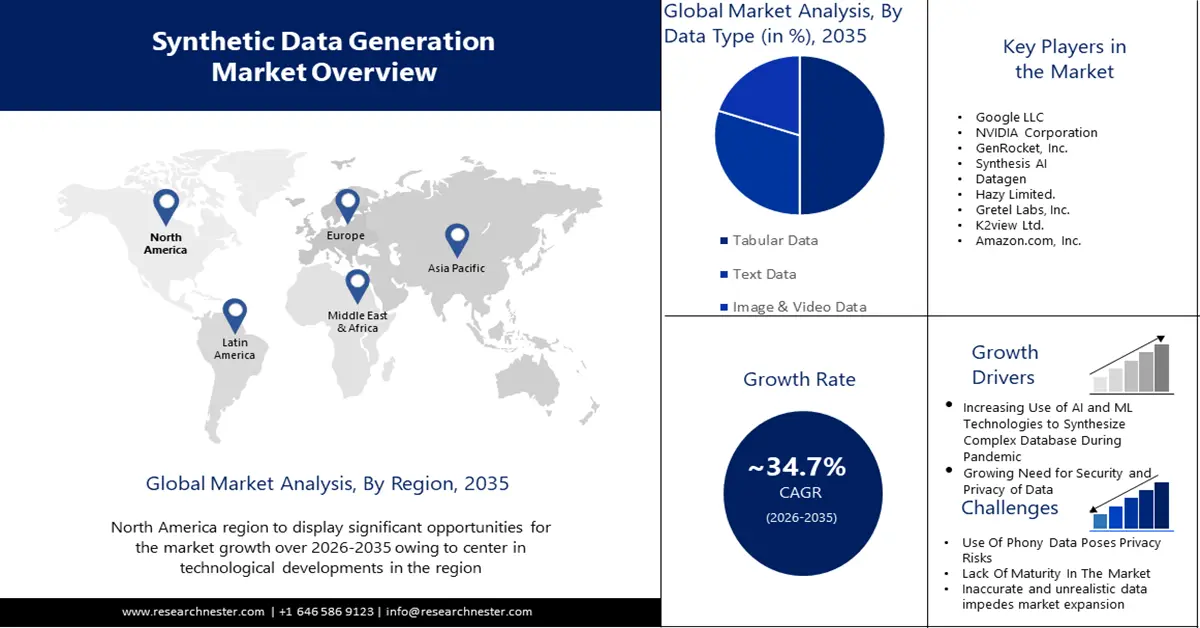
Der Markt für synthetische Datengenerierung belief sich im Jahr 2025 auf über 447,16 Millionen US-Dollar und soll bis 2035 voraussichtlich 8,79 Milliarden US-Dollar erreichen. Im Prognosezeitraum von 2026 bis 2035 wird eine jährliche Wachstumsrate (CAGR) von rund 34,7 % erwartet. Im Jahr 2026 wird der Branchenwert der synthetischen Datengenerierung auf 586,81 Millionen US-Dollar geschätzt.
Das Marktwachstum ist vor allem auf die zunehmende Nutzung synthetischer Daten bei der Kalibrierung und Entwicklung von Sensoren für autonome Fahrzeuge zurückzuführen. Darüber hinaus nutzen Automobilingenieure synthetische Daten, um virtuelle Umgebungen zu schaffen, die reale Fahrbedingungen simulieren. Schätzungen zufolge könnte autonomes Fahren bis 2035 einen Umsatz von 300 bis 430 Milliarden US-Dollar generieren. Die von der National Association of Insurance Commissioners veröffentlichte Daten gehen davon aus, dass bis 2030 4,5 Millionen selbstfahrende Fahrzeuge auf den Straßen der USA unterwegs sein werden. Diese Faktoren werden den Markt für die Generierung synthetischer Daten im Prognosezeitraum voraussichtlich ankurbeln.
Synthetische Daten werden zum Trainieren von KI-Modellen in verschiedenen Bereichen verwendet, um die Modellleistung durch die Beseitigung von Verzerrungen und die Einbindung von neuem Fachwissen zu verbessern. Zu den weiteren zunehmenden Einsatzmöglichkeiten generierter Daten gehört das Trainieren von Modellen ohne reale Daten. Laut Research Nester nutzen derzeit 34 % der Unternehmen Künstliche Intelligenz, weitere 42 % erforschen dieses Feld. Im sich schnell entwickelnden Bereich der Künstlichen Intelligenz gewinnt die Nutzung und Erstellung synthetischer Datensätze zunehmend an Bedeutung.
Schlüssel Generierung synthetischer Daten Markteinblicke Zusammenfassung:
Regionale Highlights:
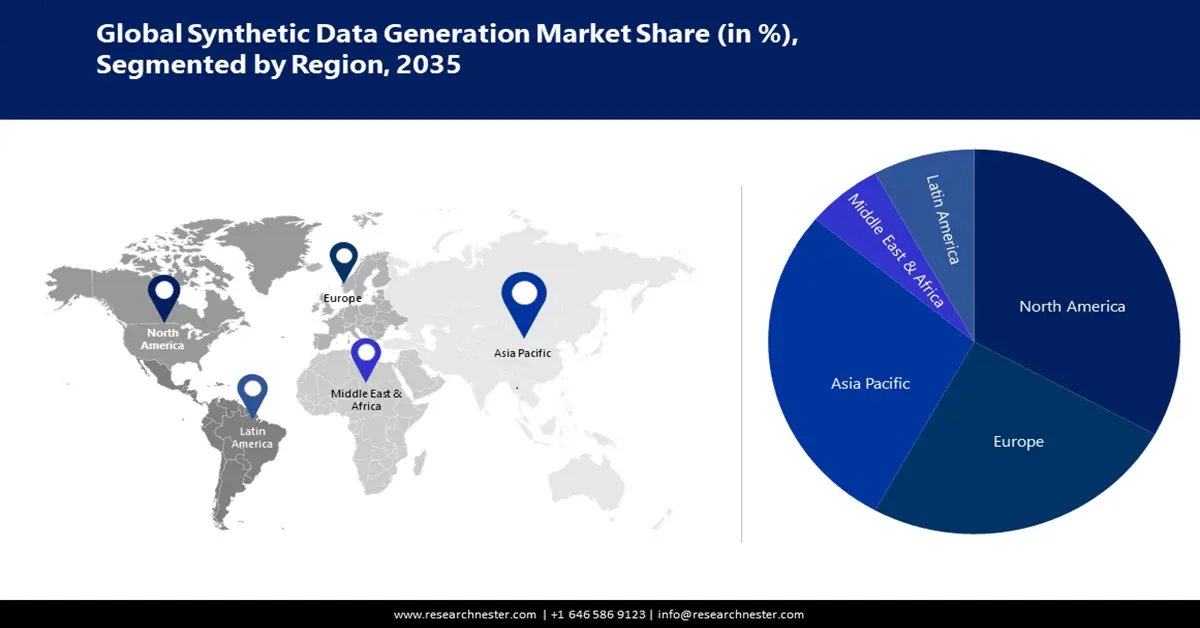
- Der Markt für synthetische Datengenerierung im asiatisch-pazifischen Raum wird im Prognosezeitraum 2026–2035 mit einem Marktanteil von über 38 % dominieren. Dies wird durch steigende Investitionen in Forschung und Entwicklung, KI-Strategien und intelligente Anwendungen synthetischer Daten vorangetrieben.
- Der nordamerikanische Markt wird im Prognosezeitraum 2026–2035 einen Marktanteil von 33 % erreichen. Dies wird durch die Konzentration von KI/ML-Innovationen und die Nachfrage nach sicheren synthetischen Daten getrieben.
Segmenteinblicke:
- Das Segment der Tabellendaten im Markt für synthetische Datengenerierung wird voraussichtlich bis 2035 einen Marktanteil von 50 % erreichen, bedingt durch den steigenden Bedarf an synthetischen Tabellendaten aufgrund von Datenschutzbedenken und Datensicherheit.
- Das Segment des Testdatenmanagements im Markt für synthetische Datengenerierung wird voraussichtlich bis 2035 einen Marktanteil von 35 % erreichen, bedingt durch den steigenden Bedarf an qualitativ hochwertigen Daten für Tests und Validierungen.
Wichtige Wachstumstrends:
- Steigender Bedarf an Datensicherheit
- Verstärkte Nutzung von Large Language Models (LLM)
Große Herausforderungen:
- Das Auftreten ungenauen und unrealistischen Daten behindert die Marktexpansion
- Damit verbundene ethische Überlegungen
Hauptakteure: Google LLC, NVIDIA Corporation, GenRocket, Inc., Synthesis AI, Datagen, Hazy Limited., Gretel Labs, Inc., K2view Ltd., Amazon.com, Inc..
Global Generierung synthetischer Daten Markt Prognose und regionaler Ausblick:
Marktgröße und Wachstumsprognosen:
- Marktgröße 2025: 447,16 Millionen USD
- Marktgröße 2026: 586,81 Millionen USD
- Prognostizierte Marktgröße: 8,79 Milliarden USD bis 2035
- Wachstumsprognosen: 34,7 % CAGR (2026–2035)
Wichtige regionale Dynamiken:
- Größte Region: Asien-Pazifik (38 % Anteil bis 2035)
- Am schnellsten wachsende Region: Asien-Pazifik
- Dominierende Länder: USA, China, Deutschland, Großbritannien, Japan
- Schwellenländer: China, Indien, Brasilien, Mexiko, Singapur
Last updated on : 16 September, 2025
Wachstumstreiber und Herausforderungen für den Markt zur Generierung synthetischer Daten:
Wachstumstreiber
Wachsender Bedarf an Datensicherheit: Synthetische Daten haben sich als wirksames Instrument erwiesen, um das Potenzial von Daten voll auszuschöpfen, ohne die Privatsphäre zu gefährden. Marktteilnehmer in verschiedenen Sektoren wie Gesundheit, Finanzen, Versicherungen usw. entscheiden sich für synthetische Daten, um deren Nutzen zu maximieren und gleichzeitig die Privatsphäre der Verbraucher zu schützen. Darüber hinaus spielen synthetische Daten eine wichtige Rolle bei der Lösung wichtiger Probleme wie Betrugserkennung und Risikomodellierung. Die alarmierende Zahl von Datenschutzverletzungen zwingt Marktteilnehmer dazu, Maßnahmen zur Risikominderung zu ergreifen. Laut einem im Februar 2024 veröffentlichten Bericht der Harvard Business Review gab es zwischen 2022 und 2023 weltweit einen Anstieg der Fälle von Datenschutzverletzungen um 20 %. Aufgrund des steigenden Bedarfs an Datensicherheit und -schutz wird für den Markt ein deutliches Wachstum prognostiziert.
Verstärkter Einsatz von Large Language Models (LLM): Anwendungsfälle für Large Language Models sind die Inhaltserstellung, Übersetzung und Lokalisierung, Chatbots, persönliche Assistenz usw. Laut Daten des Weltwirtschaftsforums vom Oktober 2023 werden soziale Netzwerke wie WhatsApp, Instagram und Facebook mit fast 30 KI-Chatbots der Muttergesellschaft Meta interagieren, um das Erlebnis ihrer Social-Media-Nutzer zu revolutionieren. Verschiedene Endbenutzer nutzen diese Sprachmodelle zur Codegenerierung, Betrugserkennung, Bildannotation, Textproduktion und Konversations-KI. Synthetische Daten machen diese Chatbots präzise und nützlich für den Verbraucher.
- Einsatz von KI- und ML-Technologien zur Synthese komplexer Datenbanken während der Pandemie: Der Ausbruch der COVID-19-Pandemie spiegelt die Merkmale der Patienten in großem Umfang wider und reproduziert die Auswirkungen der Pandemie im Laufe der Zeit und in stark betroffenen geografischen Gebieten. Die Zahl der Epidemiologen steigt weltweit sprunghaft an. So gibt beispielsweise ein im Mai 2023 veröffentlichter Bericht des US Bureau of Labor Statistics an, dass die Zahl der beschäftigten Epidemiologen 10.230 beträgt. Sie nutzen in großem Umfang synthetische Daten, um die Auswirkungen der Pandemie abzuleiten.
Herausforderungen
Das Auftreten ungenauer und unrealistischer Daten behindert die Marktexpansion: Nutzer können virtuelle Replikate von Datensätzen testen und teilen, die mithilfe synthetischer Daten erstellt wurden. Darüber hinaus ist es mit dieser Methode schwierig, die feinen Details von Spezialmodellen und realen Fotos zu erfassen. Die langfristige Pflege des synthetischen Datensatzes ist schwierig, da er auf realen Daten basiert und durch Erfindungen und Weiterentwicklungen variiert. Unternehmen sollten daher regelmäßig die Genauigkeit und Zuverlässigkeit der synthetischen Daten überprüfen. Dieser Aspekt behindert das Wachstum des Marktes für synthetische Datengenerierung erheblich, da er die Qualität und den Realismus der synthetischen Daten beeinträchtigt.
Ethische Aspekte: Die Nutzung synthetischer Daten erhöht die ethischen Aspekte des Datenschutzes und der Zustimmung zu den generierten Daten. Verschiedene Rahmenbedingungen für die Datennutzung und den Datenschutz können die Nutzung synthetischer Daten einschränken und Skalierbarkeit und Akzeptanz beeinträchtigen. Das Potenzial für Voreingenommenheit und Datenschutzbedenken dürfte das Marktwachstum hemmen.
Marktgröße und Prognose zur synthetischen Datengenerierung:
| Berichtsattribut | Einzelheiten |
|---|---|
|
Basisjahr |
2025 |
|
Prognosezeitraum |
2026–2035 |
|
CAGR |
34,7 % |
|
Marktgröße im Basisjahr (2025) |
447,16 Millionen USD |
|
Prognostizierte Marktgröße im Jahr 2035 |
8,79 Milliarden US-Dollar |
|
Regionaler Geltungsbereich |
|
Synthetische Datengenerierung-Marktsegmentierung:
Datentyp-Segmentanalyse
Basierend auf dem Datentyp wird erwartet, dass tabellarische Daten im Markt für synthetische Datengenerierung im Prognosezeitraum mit etwa 50 % den größten Umsatzanteil ausmachen. Datenschutzbedenken haben es Unternehmen in letzter Zeit erschwert, an reale Daten zu gelangen. Aufgrund dieser Schwierigkeiten werden synthetische Daten erstellt, die realen Daten ähneln und in tabellarischer Form geordnet aufbewahrt werden können. Dies erhöht den Bedarf an tabellarischen Daten, der im Prognosezeitraum voraussichtlich mit einer deutlichen durchschnittlichen jährlichen Wachstumsrate (CAGR) wachsen wird. Unternehmen können die betriebliche Datensicherheit und den Datenschutz verbessern, indem sie Generative Adversarial Networks (GANs) zur Erstellung synthetischer tabellarischer Daten nutzen.
Anwendungssegmentanalyse
Basierend auf der Anwendung wird erwartet, dass das Segment Testdatenmanagement im Prognosezeitraum mit etwa 35 % den größten Anteil am Markt für synthetische Datengenerierung einnimmt. Der steigende Bedarf an qualitativ hochwertigen Daten für Tests und Validierungen wird den Markt antreiben. Testdatenmanagement ermöglicht Entwicklern, Anwendungen mithilfe realer Daten zu testen, ohne diese zu gefährden. Die Infosys Testdatenmanagement-Suite bietet beispielsweise webbasierte Tools für die zentrale Verwaltung von Testdaten. Diese Suite bietet eine benutzerfreundliche und universelle Schnittstelle für Daten- und Testbereitstellungsteams. Das Toolkit umfasst Funktionen zur Generierung, Maskierung und Extraktion von Testdaten sowie einen datenanforderungsbasierten Workflow.
Unsere eingehende Analyse des globalen Marktes für die Generierung synthetischer Daten umfasst die folgenden Segmente:
Komponente |
|
Bereitstellungsmodus |
|
Modellierungstyp |
|
Angebot |
|
Datentyp |
|
Vertikal |
|

Vishnu Nair
Leiter - Globale GeschäftsentwicklungPassen Sie diesen Bericht an Ihre Anforderungen an – sprechen Sie mit unserem Berater für individuelle Einblicke und Optionen.
Regionale Analyse des Marktes für synthetische Datengenerierung:
Einblicke in den nordamerikanischen Markt
Dem Markt für die Generierung synthetischer Daten in Nordamerika wird mit etwa 33 % der größte Umsatzanteil zugeschrieben, da er ein Zentrum der technischen Entwicklung ist, mit besonderem Schwerpunkt auf datengesteuerten Durchbrüchen, KI und maschinellem Lernen. Aufgrund der zunehmenden Gründung von Start-ups, Technologiefirmen und Forschungseinrichtungen in dieser Region gibt es einen starken Anstieg an hochwertigen synthetischen Daten für die Durchführung von Experimenten und das Training von KI-Modellen. Die Präsenz wichtiger Marktteilnehmer treibt die Marktexpansion in der Region weiter voran. Organisationen in den USA suchen nach robusten Lösungen zum Schutz vertraulicher Informationen und zur Eindämmung von Datenpannen. Schätzungen zufolge betragen die durchschnittlichen Kosten einer Datenpanne im Land im Jahr 2024 9,32 Millionen US-Dollar. Darüber hinaus werden synthetische Daten von Forschern für Arzneimittelstudien verwendet, ohne vertrauliche Patienteninformationen preiszugeben.
Markteinblicke in den Asien-Pazifik-Raum
Der Markt für die Generierung synthetischer Daten im asiatisch-pazifischen Raum wird voraussichtlich mit etwa 38 % den zweitgrößten Umsatzanteil halten. Länder wie China und Japan sind Heimat bemerkenswerter technologieorientierter Unternehmen, die großen Wert auf Forschung und Entwicklung legen. Die Regierungen priorisieren Investitionen in Big Data, KI und Strategien für maschinelles Lernen. Synthetische Daten werden auf vielfältige Weise zur Verbesserung der Verkehrssicherheit eingesetzt. Laut der International Trade Administration vom September 2024 prognostiziert das japanische Ministerium für Inneres und Kommunikation beispielsweise, dass der japanische Markt für KI-Systeme auf fast 7,3 Milliarden US-Dollar anwachsen wird. Forscher der Universität Osaka haben ein hochmodernes Framework entwickelt, das automatisch synthetische Datensätze aus einem digitalen Zwilling einer Stadt erzeugen kann.
Marktteilnehmer für die Generierung synthetischer Daten:
- Microsoft Corporation
- Unternehmensübersicht
- Geschäftsstrategie
- Wichtige Produktangebote
- Finanzielle Leistung
- Wichtige Leistungsindikatoren
- Risikoanalyse
- Jüngste Entwicklung
- Regionale Präsenz
- SWOT-Analyse
- Google LLC
- NVIDIA Corporation
- GenRocket, Inc.
- Synthese-KI
- Datagen
- Hazy Limited.
- Gretel Labs, Inc.
- K2view Ltd.
- Amazon.com, Inc.
Neueste Entwicklungen
- Im März 2024 gaben Hazy und Unbanx ihre Zusammenarbeit bei der Open Banking-Dateneigentumsplattform bekannt. Dabei handelt es sich um eine gemeinsame Anstrengung beider Unternehmen, ethische synthetische Datenkooperativen für Finanztransaktionsdaten bereitzustellen, die Hedgefonds, Analysten und andere Finanzinstitute bedienen.
- Im Juni 2024 wurde NVIDIA Nemotron-4 340B, optimiert für NVIDIA TensorRT-LLM und NVIDIA NeMo für das Gesundheitswesen, die Fertigung, den Einzelhandel und das Finanzwesen, um unter anderem kommerzielle Anwendungen zu entwickeln.
- Im September 2024 führte Amazon Amazon Bedrock ein, ein Tool zur Generierung von Python-Code für die Erstellung synthetischer Daten. Das Amazon Bedrock-Tool unterstützt Kunden beim Erstellen und Skalieren generativer KI-Anwendungen. Es handelt sich um einen vollständig verwalteten Service zur Erstellung generativer KI-Anwendungen.
- Im Oktober 2024 haben sich Gretel und Google Cloud zusammengeschlossen, um die Generierung synthetischer Daten für Datenanalysten in BigQuery zu vereinfachen. Die Integration ermöglicht es Nutzern, datenschutzfreundliche synthetische Versionen ihrer BigQuery-Datensätze zu erstellen. Die Partnerschaft ermöglicht es den Kunden, den Datenschutz zu schützen, die Zugänglichkeit zu verbessern und Tests und Entwicklung zu beschleunigen.
- Im Oktober 2024 brachte Teledyne FLIR Prism AIMMGen auf den Markt, einen ITAR-freien Dienst zur synthetischen Datengenerierung für KI-Modelle für Systemintegratoren zur Erstellung von KI/ML-Produkten für Ersthelfer-, kommerzielle und Verteidigungsanwendungen.
- Im Oktober 2024 erhielten Betterdata, MOSTLY AI, DataCebo und Rockfish Data vom Department of Homeland Security (DHS) der Abteilung für Wissenschaft und Technologie (S&T) Aufträge zur Entwicklung synthetischer Datenfunktionen, die reale Datenmuster generieren und gleichzeitig Sicherheitsbedrohungen mindern können. Die datenschutzfreundlichen generativen Datenplattformen sollen die KI-Funktionen in Unternehmensanwendungen beschleunigen.
- Report ID: 5711
- Published Date: Sep 16, 2025
- Report Format: PDF, PPT
- Entdecken Sie eine Vorschau auf die wichtigsten Markttrends und Erkenntnisse
- Prüfen Sie Beispiel-Datentabellen und Segmentaufgliederungen
- Erleben Sie die Qualität unserer visuellen Datendarstellungen
- Bewerten Sie unsere Berichtsstruktur und Forschungsmethodik
- Werfen Sie einen Blick auf die Analyse der Wettbewerbslandschaft
- Verstehen Sie, wie regionale Prognosen dargestellt werden
- Beurteilen Sie die Tiefe der Unternehmensprofile und Benchmarking
- Sehen Sie voraus, wie umsetzbare Erkenntnisse Ihre Strategie unterstützen können
Entdecken Sie reale Daten und Analysen
Häufig gestellte Fragen (FAQ)
Generierung synthetischer Daten Umfang des Marktberichts
Die kostenlose Stichprobe umfasst aktuelle und historische Marktgrößen, Wachstumstrends, regionale Diagramme und Tabellen, Unternehmensprofile, segmentweise Prognosen und mehr.
Kontaktieren Sie unseren Experten




Urheberrecht © 2026 Research Nester. Alle Rechte vorbehalten.
